The analysis in this report is based on nationally representative telephone surveys in the United States, Germany and Italy. Descriptions of the methodology used in each country are below.
United States
Nationally representative telephone interviews were conducted October 27-November 24, 2014, among a national sample of 1,692 adults, 18 years of age or older, living in all 50 U.S. states and the District of Columbia (675 respondents were interviewed on a landline telephone, and 1,017 were interviewed on a cell phone, including 568 who had no landline telephone). The survey was conducted by interviewers at Princeton Data Source under the direction of Princeton Survey Research Associates International. Interviewing was conducted in two stages, as described below. In both stages, a combination of landline and cell phone random digit dial samples were used; both samples were provided by Survey Sampling International. Interviews were conducted in English and Spanish.
The first stage consisted of 1,500 interviews (614 on a landline telephone and 886 on a cell phone). Respondents in the landline sample were selected by randomly asking for the youngest adult male or female who is now at home. Interviews in the cell sample were conducted with the person who answered the phone, if that person was an adult 18 years of age or older.
In the second stage of interviewing, the samples were screened for people between the ages of 40 and 64 who had at least one living parent ages 65 or older and at least one child. A total of 192 were completed during this stage (61 from the landline sample and 131 from the cell sample). The data collecting stopped when a total of 500 respondents in the target group was achieved.
The combined landline and cell phone sample are weighted using an iterative technique that matches gender, age, education, race, Hispanic origin and nativity and region to parameters from the 2013 Census Bureau’s American Community Survey and population density to parameters from the Decennial Census. The sample also is weighted to match current patterns of telephone status (landline only, cell phone only, or both landline and cell phone), based on extrapolations from the 2014 National Health Interview Survey. The weighting procedure also accounts for the fact that respondents with both landline and cell phones have a greater probability of being included in the combined sample and adjusts for household size among respondents with a landline phone. A separate adjustment was made to account for the oversampling of adults ages 40 to 64 with at least one living parent ages 65 or older and at least one child so they represent the proportion in the main sample. The adjustment was made separately for the landline and cell sample frames. The margins of error reported and statistical tests of significance are adjusted to account for the survey’s design effect, a measure of how much efficiency is lost from the weighting procedures.
For detailed information about our survey methodology, see https://www.pewresearch.org/methodology/u-s-survey-research/.
Germany
Nationally representative telephone interviews were conducted November 10-December 11, 2014, among a national sample of 1,700 adults, 18 years of age or older, living in Germany (1,356 respondents were interviewed on a landline telephone, and 344 were interviewed on a cell phone). The survey was conducted by interviewers at Emnitel under the direction of TNS Emnid, Bielefeld. Interviewing was conducted in two stages, as described below. In both stages, a combination of landline and cell phone random digit dial samples were used; both samples were based on the ADM Master Sample. Interviews were conducted in German. At least five attempts were made to complete an interview at every sampled telephone number.
The first stage consisted of 1,534 interviews (1,218 on a landline telephone and 316 on a cell phone). Respondents in the landline sample were selected at random within the household. Interviews in the cell sample were conducted with the person who answered the phone, if that person was an adult 18 years of age or older.
In the second stage of interviewing, the samples were screened for people between the ages of 40 and 64 who had at least one living parent ages 65 or older and at least one child. A total of 166 were completed during this stage (138from the landline sample and 28 from the cell sample). The data collecting stopped when a total of 500 respondents in the target group was achieved.
The samples are weighted to account for probability of being included in the sample and using an iterative technique to correct known demographic discrepancies. In particular, gender, age, education, region, and city size were matched to 2012 parameters from Federal Statistical Office (Statistisches Bundesamt). A separate adjustment was made to account for the oversampling of adults ages 40 to 64 with at least one living parent ages 65 or older and at least one child so they represent the proportion in the main sample. The adjustment was made separately for the landline and cell sample frames. The margins of error reported and statistical tests of significance are adjusted to account for the survey’s design effect, a measure of how much efficiency is lost from the weighting procedures.
Italy
Nationally representative telephone interviews were conducted November 3-December 18, 2014, among a national sample of 1,516 adults, 18 years of age or older, living in Italy (1,141 respondents were interviewed on a landline telephone, and 375 were interviewed on a cell phone). The survey was conducted by the Laboratorio Analisi Politiche e Socialie (LAPS) at the University of Siena. The landline sample was randomly drawn from the Italian telephone registry, while a pure random digit dial was used to create the cell phone sample. Interviews were conducted in Italian. Respondents in the landline sample were selected by randomly asking for the person in the household who had the last birthday. At least ten attempts were made to complete an interview at every sampled telephone number.
The samples are weighted to account for probability of being included in the sample and to correct known demographic discrepancies. In particular, gender, age, education, and region were matched to parameters from the National Institute of Statistics (Istat) using an iterative weighting technique. The margins of error reported and statistical tests of significance are adjusted to account for the survey’s design effect.
For detailed information about our survey methodology for international studies, see https://www.pewresearch.org/methodology/international-survey-research/.
Sample Sizes and Margins of Error for Key Groups
The following table shows the unweighted sample sizes and the error attributable to sampling that would be expected at the 95% level of confidence for different groups in the survey:
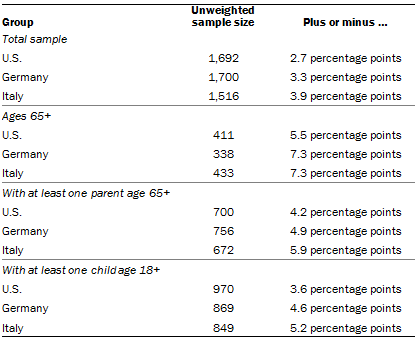
Sample sizes and sampling errors for other subgroups are available upon request.
In addition to sampling error, one should bear in mind that question wording and practical difficulties in conducting surveys can introduce error or bias into the findings of opinion polls.
Pew Research Center is a nonprofit, tax-exempt 501(c)3 organization and a subsidiary of The Pew Charitable Trusts, its primary funder.
© Pew Research Center, 2015






