Results for this study are based on telephone interviews conducted by Social Science Research Solutions (SSRS), an independent research company, among a nationally representative sample of 5,103 Latino respondents ages 18 and older. It was conducted on cellular and landline telephones from May 24 through July 28, 2013. The survey covers a range of topics including Hispanics’ religious affiliation and behaviors, views of Hispanic identity, and views about social issues. The survey used a stratified sampling design, oversampling areas with higher densities of Latino residents and oversampling areas with a higher concentration of Latinos with a non-Mexican heritage. The survey also included an oversample of non-Catholic Latinos. Several stages of statistical adjustment or weighting were used to account for the complex nature of the sample design, including a correction for oversampling and other differences in the probability of selection as well as sample balancing to population totals for the U.S. Hispanic adult population.
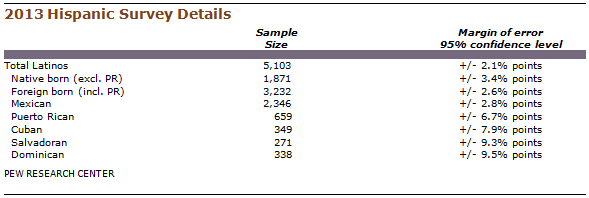
For the full sample, a total of 1,871 respondents were native born (excluding Puerto Rico), and 3,232 were foreign born (including Puerto Rico). Also 2,346 were of Mexican origin, 659 were Puerto Rican, 349 were Cuban, 271 were Salvadoran, and 338 were Dominican. For results based on the total sample, one can say with 95% confidence that the error attributable to sampling is plus or minus 2.1 percentage points.
For this survey, SSRS used a staff of Spanish-speaking interviewers who, when contacting a household, were able to offer respondents the option of completing the survey in Spanish or English. A total of 2,725 respondents (53%) were surveyed in Spanish, and 2,378 respondents (47%) were interviewed in English. Any person ages 18 or older of who said they are of Latino origin or descent was eligible to complete the survey.
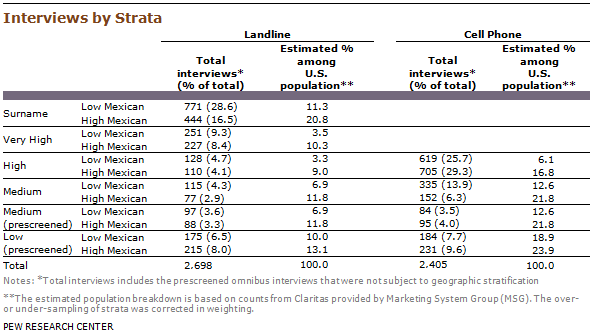
To ensure the highest possible coverage of the eligible population, the study employed a dual-frame landline/cellular telephone design. The sample consisted of a landline sampling frame (yielding 2,698 completed interviews) and a cell phone sampling frame (2,405 interviews).4 Both the landline and cell phone sampling frames used a stratified sampling design, oversampling areas with higher densities of Latino residents. The same sampling plan was used for the main sample and the non-Catholic oversample.
For the landline sampling frame, the sample was compared with InfoUSA and other household databases, and phone numbers associated with households that included persons with known Latino surnames were subdivided into a Surname stratum. The remaining unmatched and unlisted landline sample was divided into the following mutually exclusive strata, based on U.S. Census Bureau estimates of the density of the Hispanic population in each: Very High, High and Medium Latino.5 These strata were then further subdivided into Low Mexican and High Mexican strata.
The Marketing System Group (MSG) GENESYS sample generation system was used to generate cell phone sample, which was divided into High and Medium Latino strata. These were further divided into Low Mexican and High Mexican strata.
Samples for the low-incidence landline and low-incidence cell strata were drawn from previously interviewed respondents in SSRS’s weekly dual-frame Excel omnibus survey. Respondents who indicated they were Latino on the omnibus survey were eligible to be re-contacted for the present survey. In addition, the incidences in the Medium landline and cell phone strata were lower than anticipated, so additional interviews with Latinos prescreened from the Excel omnibus survey were used to gather additional interviews in these strata. This resulted in a total of two additional strata for both the landline and cell phone sampling frames. The number of interviews completed in each stratum is shown in the table below.
It is important to note that the existence of a surname stratum does not mean the survey was a surname sample design. The sample is RDD, with the randomly selected telephone numbers divided by whether or not they were found to be associated with a Spanish surname. This was done simply to increase the number of strata and thereby increase the ability to meet ethnic targets and ease administration by allowing for more effective assignment of interviewers and labor hours.
A multi-stage weighting procedure was used to ensure an accurate representation of the national Hispanic population.
- An adjustment was made for all persons found to possess both a landline and a cell phone, as they were twice as likely to be sampled as were respondents who possessed only one phone type.
- The sample was corrected for a potential bias associated with re-contacting previously interviewed respondents in certain strata.
- The sample was corrected for the likelihood of within-household selection, which depended upon the likelihood that the respondent’s age group would be selected, and within that age group, the particular respondent would be selected.
- The sample was corrected for the oversampling of telephone number exchanges known to have higher densities of Latinos and the corresponding undersampling of exchanges known to have lower densities of Latinos.
- Finally, the data were put through a post-stratification sample balancing routine to population totals for the U.S. Hispanic adult population based on the 2012 U.S. Census Bureau’s Current Population Survey, March Supplement. Iterative proportional fitting, or raking, was completed for the following parameters: age by state (California, Florida, New York, Texas and all other states combined), gender by state, heritage by state, education by state, U.S. born or years in the U.S. by state, Census region, phone use (i.e., cell phone only, cell phone mostly, mixed/landline only/landline mostly) and density of the Latino population.
- Both the base weights and the post-stratification weights were trimmed to range from 0.10 to 5.0.
The data were weighted in two steps. In the first step, it was weighted to resemble the population distribution of the U.S. Hispanic adult population. In the second step, the weighted data were used to determine the benchmark for a Catholic/non-Catholic parameter, which was used in adjustments to weights for the oversample of non-Catholic Latinos.






