The analysis in this report is based on a Pew Research Center survey conducted online Feb. 6-April 6, 2015 among a probability based sample of 1,555 multiracial Americans ages 18 and older. The sample of multiracial adults was identified after contacting and collecting basic demographic information from 21,224 adults nationwide. For comparative purposes, an additional 1,495 adults from the general public were surveyed, including oversamples of 154 adults who are single-race black and non-Hispanic and 208 adults who are as single-race Asian and non-Hispanic.
The survey was conducted by the GfK Group for the Pew Research Center using KnowledgePanel, its nationally representative online research panel. KnowledgePanel members are recruited through probability sampling methods and include individuals both with and without internet access. KnowledgePanel provides internet access for those who do not have it and, if needed, a device to access the internet when they join the panel. A combination of random digit dialing (RDD) and address-based sampling (ABS) methodologies have been used to recruit panel members (in 2009 KnowledgePanel switched its sampling methodology for recruiting panel members from RDD to ABS). The panel includes households with landlines and cellular phones, including those only with cell phones, and those without a phone. Both the RDD and ABS samples were provided by Marketing Systems Group (MSG). KnowledgePanel continually recruits new panel members throughout the year to offset panel attrition as people leave the panel. The survey was conducted in English and Spanish.
All active members of the GfK panel were eligible for inclusion in this study. This project was divided into two stages. For Stage 1 a sample of general population adults age 18 and over was selected along with oversamples of non-Hispanic single-race blacks and Asians that were identified using GfK’s panelist profile data. Stage 2 consisted of a general population sample that was split randomly into four replicates of approximately 8,000 panel members each.
Those selected for each replicate were asked their race or origin, the race or origin of their biological mother and father as well as the race or origin of their grandparents, great-grandparents and earlier ancestors. At each stage respondents could select more than one race or origin. In addition, those with a Hispanic background were asked if they considered Hispanic to be their race, their ethnicity, or both their race and ethnicity. Only those who were identified as having a mixed-race background based on these initial screening questions qualified to continue on to take the main multiracial survey. Slightly different qualifying criteria were used for some of the replicates, as described in the next section.
I. Defining Multiracial Adults
To determine their racial background, a series of five screening questions were asked of all 21,224 GfK panelists selected to participate in the online survey.
The first question asked individuals to select their own race or origin and is reproduced below as it appeared on the questionnaire. Respondents were asked about each of their biological parent’s race or origin, their grandparents’ race or origin, and the race or origin of great-grandparents or any earlier ancestors, if different than any of the races indicated in the previous questions. The same choice options, including the option to mark ‘Hispanic,” were used in all five questions; to avoid repetition, the option list only appears with the first question. While respondents had the option to mark “Some other race or origin” in each question, the option to list any other race(s) or origin(s) was only offered on the first question. Respondents could mark as many races or origins as applied and were instructed to consider only the background of their biological parents, grandparents or earlier ancestors.
The screening questions were:
- What is your race or origin?
[Mark ONE OR MORE boxes.]
- White Examples: German, Irish, English, Italian, Lebanese, Egyptian, and so on
- Hispanic, Latino, or Spanish origin Examples: Mexican or Mexican American, Puerto Rican, Cuban, Dominican, Salvadoran, Colobian, and so on
- Black or African American Examples: African American, Jamaican, Haitian, Nigerian, Ethiopian, Somalian, and so on
-
Asian or Asian American Examples: Chinese, Filipino, Asian Indian, Vietnamese, Korean, Japanese, and so on
- American Indian Examples: Navajo Nation, Blackfeet Tribe, Muscogee (Creek) Nation, Mayan, Doyon, Native Villlage of Barrow Inupiat Traditional Government, and so on
- Native Hawaiian or Other Pacific Islander Examples: Native Hawaiian, Samoan, Guamanian or Chamorro, Tongan, Fijian, Marshallese, and so on
- Some other race or origin List race(s) and/or origin(s)
- How would you describe your MOTHER’S race or origin? [Please mark the race or races of your BIOLOGICAL OR BIRTH MOTHER and not a stepmother or adoptive mother.]
- How would you describe your FATHER’S race or origin? [Please mark the race or races of your BIOLOGICAL OR BIRTH FATHER and not a stepfather or adoptive father.]
- How would you describe the races or origins of your GRANDPARENTS? For example, to indicate all of your grandparents were white, only mark White. To indicate one was Asian and the rest were white, mark Asian and White. To indicate one was white and black and the remainder were Asian, mark White, Black and Asian. Please include ALL of the races that apply, including any you have already mentioned in previous answers. [Please mark the races or origins of your BIOLOGICAL OR BIRTH GRANDPARENTS and not step-grandparents or adoptive grandparents.]
- Thinking about your family history, as far as you know were any of your GREAT GRANDPARENTS or EARLIER ANCESTORS a different race or origin than you, your parents or your grandparents? ASK IF GREAT GRANDPARENTS OR EARLIER ANCESTORS WERE A DIFFERENT RACE: How would you describe the races or origins of your GREAT GRANDPARENTS or EARLIER ANCESTORS who were a different race or origin than you, your parents or your grandparents? [Please indicate ONLY RACES OR ORIGINS OTHER THAN THOSE YOU HAVE GIVEN ABOUT YOU AND YOUR FAMILY MEMBERS IN PREVIOUS ANSWERS and only the races or origins of BIOLOGICAL OR BIRTH RELATIVES and not step or adoptive relatives]
Those with a Hispanic background as indicated in their responses to any of the previous five questions were asked:
- Which best describes your Hispanic background?
- Being Hispanic is part of my RACIAL background, just like other people consider being black, white or Asian to be part of their racial background
- Being Hispanic is part of my ETHNIC background, just like other people consider being Scandinavian, Irish or German to be part of their ethnic background
- Being Hispanic is part of BOTH my racial and ethnic backgrounds
- Don’t know/unsure
To qualify as multiracial for the purposes of taking the survey (though the definitions used in the report are somewhat narrower), a panel member in Replicate 1 must have met one of the following criteria:
- Selected two or more census races for themselves. The races are white, Black or African American, Asian or Asian American, American Indian, and Native Hawaiian or Other Pacific Islander.
- Did not fit the definition of multiracial based on criteria 1 but indicate any of the following:
- At least one of their parents was not the same race as the one they selected for themselves.
- Report that their parents were not the same race as each other.
- Select two or more races for at least one of their parents.
- Did not fit the definition of multiracial based on criteria 1 or 2 but indicate either of the following:
- At least one of their grandparents was not the same race as themselves or their parents.
- Select two or more races for their grandparents.
- Did not fit the definition of multiracial based on criteria 1, 2 or 3 but indicate either of the following:
- At least one of their great-grandparents or earlier ancestors was not the same race as themselves, their parents, or their grandparents.
- Select two or more races for their great-grandparents or earlier ancestors.
In addition, Hispanics could continue on to take the full multiracial survey in Replicate 1 if they did not fit the definition of multiracial based on criteria 1-4 but considered being Hispanic a race and met one of the following criteria:
- Selected Hispanic and one census race for themselves.
- Did not fit the definition of multiracial based on criteria 5 but indicate any of the following:
- At least one of their parents was Hispanic and one census race.
- Select Hispanic and no census race for one parent and selected a census race but not Hispanic for the other parent.
- Select Hispanic and no census race for themselves but report one census race for at least one of their parents.
- Select one census race and not Hispanic for themselves but report that at least one parent was Hispanic.
- Did not fit the definition of multiracial based on criteria 5 or 6 but indicate any of the following:
- Select Hispanic and one census race for their grandparents.
- Select Hispanic and no census race for themselves or their parents but report a census race for their grandparents.
- Select one census race and not Hispanic for themselves but report that a grandparent was Hispanic.
- Did not fit the definition of multiracial based on criteria 5,6 or 7 but indicate any of the following:
- Select one census race and Hispanic for their great-grandparents or earlier ancestors.
- Select Hispanic and no census race for themselves, their parents or grandparent but indicate that at least one great-grandparent or earlier ancestor was one census race.
- Select one census race and not Hispanic for themselves, their parents or grandparent but indicate that at least one great-grandparent or earlier ancestor was Hispanic.
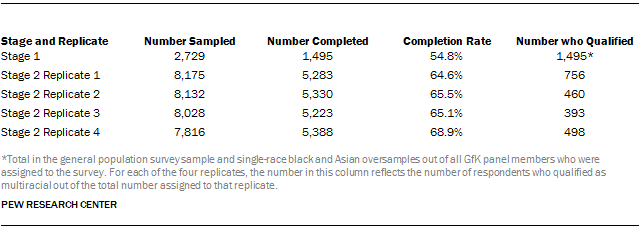
In Replicates 2 and 4, a panel member would qualify to take the multiracial survey if they fit the definition of multiracial based on criteria 1-3 or 5-7. Those who only met the great grandparent or earlier ancestor criteria (4 and 8) did not qualify.
In Replicate 3, only those who met criteria 1-3 qualified for the multiracial survey.
For purposes of analysis, those who qualified as multiracial on the basis of the racial makeup of great-grandparents or earlier ancestors (criteria 4 and 8) were not part of the multiracial sample.
All sampled members received an initial email to notify them of the survey and provide a link to the survey questionnaire. Follow-up reminders were sent after three and seven days to those who had not yet responded.
II. Weighting
Individuals included in the Stage 1, nationally representative sample were first assigned base weights that account for their probability of selection from the overall panel. This includes weighting down single-race blacks and Asians to account for the fact that they were oversampled. Next, cases that completed the survey were weighted to match the March 2014 Current Population Survey (CPS) in order to correct for potential bias due to nonresponse.
The overall sample of respondents was weighted to match CPS estimates of the following characteristics:
- Age (18-29, 30-44, 45-59, 60+) by Gender
- Race/Ethnicity (White/ non-Hispanic, Black/ non-Hispanic, Other/ non-Hispanic, Hispanic, Mixed Races/non-Hispanic).
- Education (Less than high school graduate, high school graduate, Some college, Bachelor’s degree or higher)
- Language Proficiency (English Proficient Hispanic, Bilingual Hispanic, Spanish Proficient Hispanic, Non-Hispanic) Language proficient distributions are based on Pew Research Center 2010-2012 data of U.S. Hispanic adults ages 18 and older.
Additionally, individual racial and ethnic groups were weighted to be internally representative on the following variables:
- Age (18-29, 30-44, 45-59, 60+)
- Gender (Male, Female)
- Census Region (Northeast, Midwest, South, West; Northeast and Midwest regions were combined for Hispanics]
- Metropolitan Status (Metro, Non-Metro; Hispanics were not weighted on this variable)
- Education (High school graduate or less, Some college, Bachelor’s degree or higher)
- Household Income (under $25,000, $25,000-$49,999, $50,000-$74,999, $75,000+)
The groups were: non-Hispanic whites, non-Hispanic blacks, non-Hispanic other or mixed races, and Hispanic.
For the Stage 2 sample, the weighting process was similar. The full, sample of 21,224 respondents was weighted to be nationally representative using the characteristics listed above.
For the Stage 2 samples, five race/ethnicity groups were weighted to be internally representative: non-Hispanic whites, non-Hispanic blacks, non-Hispanic other, Hispanic, and non-Hispanic mixed races.
After the full Stage 2 sample was weighted to be nationally representative, respondents who did not qualify for inclusion in their replicate were removed. At this point, a final adjustment was made to account for the fact that the criteria for inclusion differed across replicates, ensuring individuals who qualified under different criteria were represented proportionally.
Details about the GfK panel-level weights can be found at: http://www.gfk.com/Documents/GfK-KnowledgePanel-Design-Summary.pdf
III. Sampling Error and Design Effects
Weighting to adjust for disproportionate sampling and nonresponse reduces the precision of estimates beyond what would be achieved under simple random sampling. In this report, all measures of sampling error and statistical tests of significance take into account the design effect of weighting.
The margin of sampling error at the 95% confidence level for results based on the total Stage 2 sample (n=21,224) is plus or minus 1 percentage point.
The margin of sampling error for results based on the general population sample and single-race black and white oversamples (n=1,495) is plus or minus 3 percentage points.
The margin of sampling error for results based on the multiracial sample (n= 1,555) is plus or minus 3.8 percentage points.
The sample sizes and margins of sampling error for the six largest multiracial groups referenced in this report are:

In addition to sampling error, question wording and the practical difficulties in conducting surveys can introduce error or bias into the findings of opinion polls.
